前几天试着做了一下web的语音识别服务,发现里面还是有不少坑的,因此想写一下web语音识别现状,并对几个语音识别框架作简要分析。
annyang
如果在 GitHub 上搜索 Speech recognition ,最受欢迎的前端语音识别库就是 annyang,这个仓库有5.1k star,看着这么多star想着这个语音识别库一定非常好用,于是我就开始了 annyang 的爬坑之旅。
首先我在前面先说一下 annyang 这个语音识别库的问题,主要有两点:
- 对于三大浏览器,只兼容
Chrome浏览器,不兼容IE和火狐 - 需要翻墙才能使用
总的来说 annyang 的文档写的还算详细,照着文档一步一步做也能做出理想的效果,但是由于其以上两个问题,因此放弃了对这个框架的进一步探索。
接下来我就探索了一下,为什么这个库会有这样的问题:
首先第一点,annyang 是基于 H5 的 Speech Recognition API,下面这张图说明了这个API的兼容性:
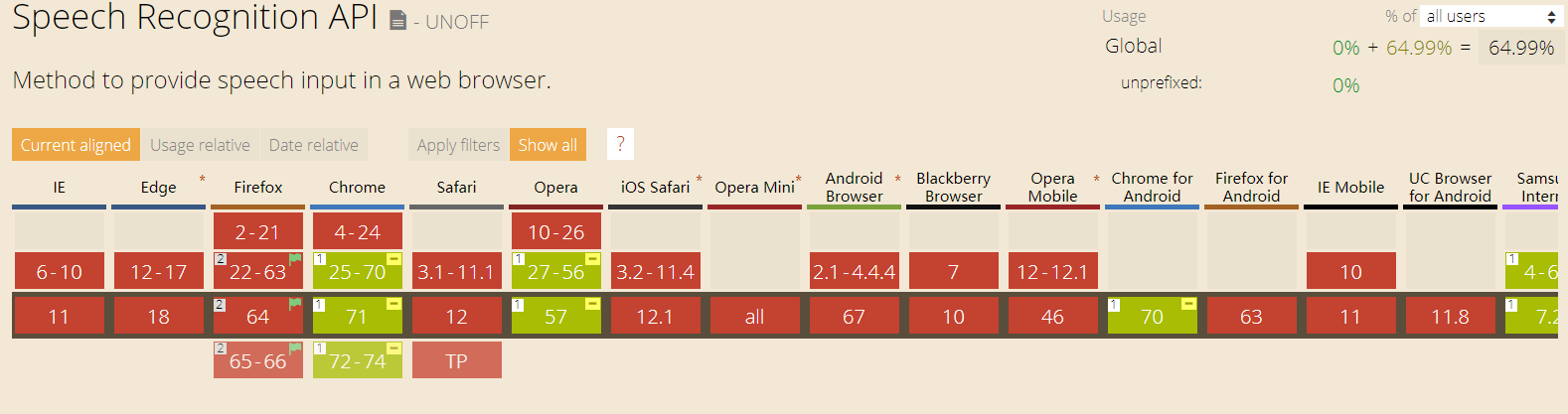
可以看到,大部分浏览器都不支持 Speech Recognition。
接着我们来看一下 MDN 官方文档上怎么说

大概意思是说 Speech Recognition 基于一个识别引擎,这个识别引擎我们推测是Chrome的,因此这就说明了Speech Recognition 只有翻墙才能使用。
因此基于 Speech Recognition 的语音识别我们是无法采用的。
接下来看一下国内的语音识别服务。
腾讯语音识别
国内的语音识别服务都不是直接的语音识别,怎么说呢,就是需要你上传音频文件到它的指定接口,然后将音频文件的内容识别出来。因此我们就需要改变一下语音识别策略,首先在前端我们需要将用户说的话给录下来,然后生成音频文件传给腾讯服务的接口,但是呢,由于浏览器存在同源策略,我们不能直接将音频文件传给腾讯的接口,所以我们需要一个中间层来帮助我们转发请求,所以现在语音识别的基础流程是:
- 前端生成音频文件传给后台
- 后台接受音频文件转发给腾讯语音识别
api - 腾讯语音识别
api返回结果给后台 - 后台返回结果给前端
这里的后台我用的是NodeJS,但是在用腾讯语音识别时,首先需要接口鉴权,我们看一下接口鉴权的具体内容:

看到这些我内心是崩溃的,感觉超级麻烦。但是最后还是照着做了,做了之后就各种鉴权有问题,然后纠结了半天,换成了科大讯飞的语音识别。
科大讯飞语音识别
我选的是科大讯飞的语音听写api,然后也是要接口认证,当然,认证过程没有腾讯那么麻烦,但是也是不少坑,我最终也是掉进去了走不出来。

最后我终于想到了百度语音识别,然后开始了最后的尝试。
百度语音识别
首先说明一下,百度语音识别是及其友好的,没有上面的那些授权认证什么的,如果是用NodeJS写后台的话,只需要通过 npm 安装 baidu-aip-sdk 即可调用相应的语音服务。这里在官方文档上有一个demo。同时大家也可以参考一下我做的一个完整的前后台语音识别demo。
因此最终我选择了百度语音识别,因为其他两个弄了半天也没弄好。
所以我建议大家如果用NodeJS来做后台的话,可以优先选择百度语音识别。